牛牛app
真钱牛牛官网 RAG 只是权宜之策


在我第一个坐蓐级 RAG 系统上线三个月后,我在晚上 11 点收到了告警。
一个企业客户的聊天机器东谈主检索到了一条完满针对不同职工层级的 HR 战略。谈话充足相似,以致于检索器以为匹配。本体上并莫得。我花了两天时候调优,更小的分块、更大的近似、不同的镶嵌模子。问题不断发生。
当时我意志到,我并不是在建设一个 bug。裂缝存在于架构自身,位于任何分块大小王人无法涉及的深处。
直到我战争到苹果的 CLaRa 和一种名为 Golden Retriever RAG 的时刻,我才终于大彻大悟。一朝你看清这一丝,就无法有目无睹。络续阅读,了解这个裂缝究竟是什么,为什么每个流行的建设决策王人只是障翳它,以及 CLaRa 究竟作念了什么不同的事情。
1、为什么 LLM 需要 RAG?(压缩问题)
要交融 RAG 为什么有裂缝,你需要交融 LLM 究竟是什么。大大量诠释跳过这一部分,凯旋跳到经由。那是一个罅隙。
大谈话模子不是数据库。它们不存储事实。它们莫得写着"法国的王人门是巴黎"的查找表。
它们本体作念的是压缩。
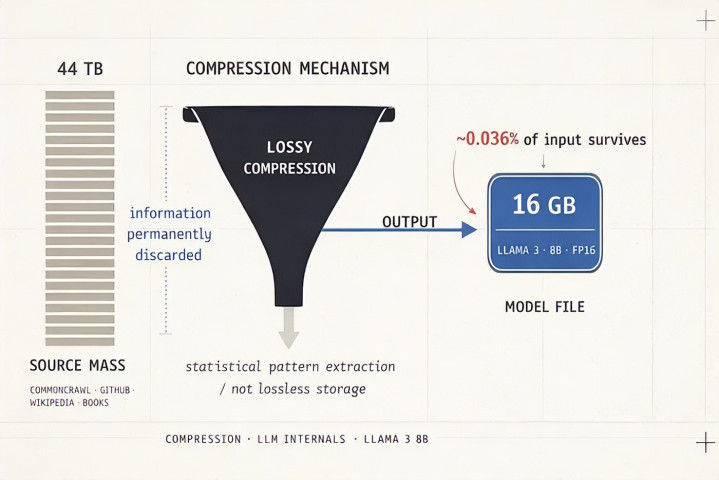
以 LLaMA 3 8B 为例。它在大略 15 万亿个 token 上西宾,这些 token 代表从 CommonCrawl、GitHub、维基百科、册本和类似着手获取的约 44 TB 的互联网文本。最终模子文献在 FP16 精度下?大略 16 GB。
花一秒想想这个比例。你把 44 TB 的东谈主类常识压缩到 16 GB。这不是无损操作。你用 zip 文献作念不到这一丝。正在发生的是有损压缩,类似于将 JPEG 压缩到最大。模子不会记着事实。它学习统计款式。它学会在"法国的王人门是"之后,token "巴黎"有很高的概率紧随后来。全是统计学。
这在生成教导、崎岖文允洽的文本时成果很好。当你需要具体的、事实性的回忆时,它就崩溃了。一个精准的日历。一个契约条件。你公司刻下的订价表。信息要么太忽视,无法在压缩中齐全保留,要么在西宾数据网罗时根底不存在。
这等于 RAG 被发明来处理的问题。
2、幻觉不是 Bug。它们是预期输出
幻觉不是要建设的故障。它们是有损压缩器被要求重建它不再领有的数据时的可瞻望收尾。
把一张像片压缩到原大小的 5%,然后放大。图像不会崩溃。它会捏造。它用从未存在过的、看似合理的款式填充缺失的像素。块状、混沌、充满伪影。LLM 产生幻觉恰是如斯。不是坏了。只是压缩系统被动填补空缺时的平时阐扬。
对于创意写稿,这没问题。对于企业文档、患者纪录或法律契约,这是一个严重问题。这等于检索增强生成存在的原因:在查询时将简直的文本交给模子,而不是让它从记念中重建。

3、什么是轮番 RAG,为什么它大部分时候能用?
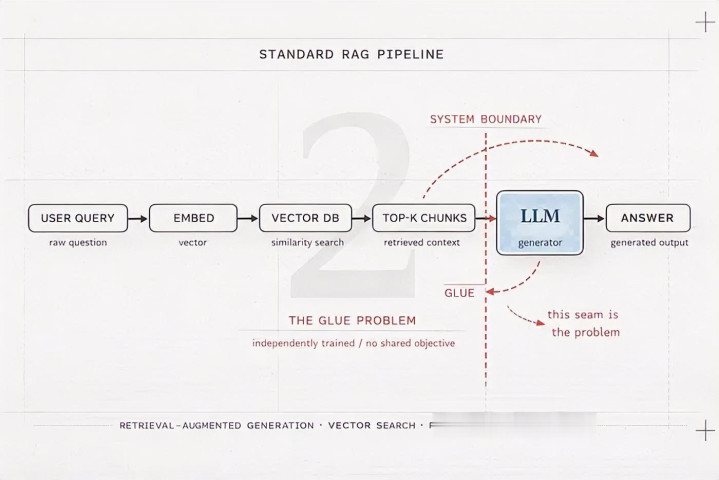
检索增强生成将 LLM 视为开卷锤真金不怕火中的学生。不是从记念中回忆,而是在查询时将相关页面交给它。
经由:
用户提交查询
查询被镶嵌成向量
向量数据库找到相似的文档分块
匹配的分块被粘贴到 LLM 的崎岖文窗口中
LLM 仅基于该崎岖文恢复
它有用。新文档无需从头西宾即可立即使用。这照实很有用。
但 RAG 是一个权宜之策。你将两个基于完满不同原则构建的系统粘合在通盘:一个作念向量空间数学的检索器和一个作念概率 token 瞻望的生成器。它们不是为彼此联想的。这种不匹配有一个大大量教程从不畏缩诠释的后果。
4、RAG 的简直问题是什么?(梯度墙)
这是本体的裂缝。分块调优无法涉及的阿谁。
当代深度学习之是以有用,是因为反向传播。每当神经聚集犯错时,蚀本函数管帐算输出有多错。该错误信号通过聚集每一层向后传播,使用链式法例诡计每个权重对罅隙的孝顺进度。然后相应地调整每个权重。
这个过程唯有在链中的每一步王人是可微的时才有用:平滑、贯穿,数学上充足艰深,梯度不错流过。
面前望望 RAG 经由中检索时会发生什么。
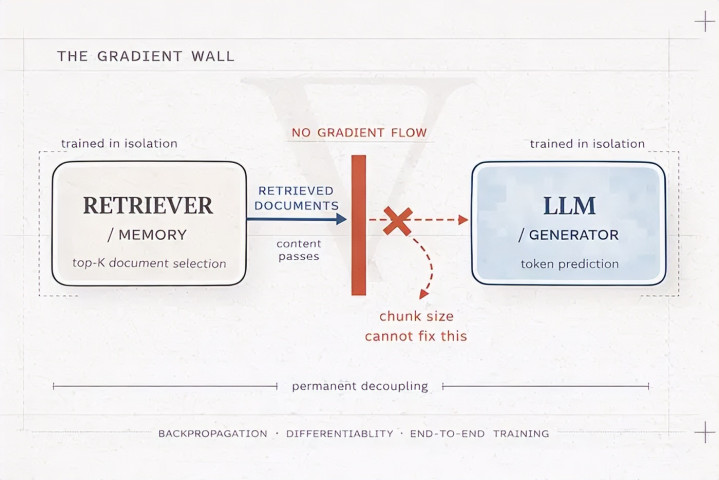
检索器凭据传入的查询为数据库中的每个文档打分。你可能有 10 万个文档。每个王人获取一个相似度分数。然后系统采取top K 收尾。K 等于 5,或 10,或你配置的任何值。等于这么。高于阁下线的文档插足。其他一切王人被丢弃。
阿谁"采取 top K"的方法是一个硬性的、打破的采取。文档要么在,要么不在。莫得平滑过渡。莫得分数文档。莫得梯度不错流过的贯穿函数。
是以当检索器拉取不相关的文档,LLM 产生罅隙谜底时,阿谁谬污蔑发生什么?LLM 莫得机制将罅隙信号发送回检索器。数学根底不允许。梯度在两个系统的规模处腐烂。
检索器始终不知谈它犯了罅隙。下次相通的查询进来时,它犯相似的罅隙。LLM 不可说"阿谁文档错了,调整你的权重"。莫得调整。莫得学习。两个组件永远解耦,孤苦孤身一人西宾,这种高低被烘焙进架构中。
这等于中枢问题。不是你的分块大小。不是你的镶嵌模子。不是你的相似度阈值。
梯度无法流动。系统无法端到端学习。其他一切王人是由此产生的。
5、GraphRAG 真的处理了检索问题吗?
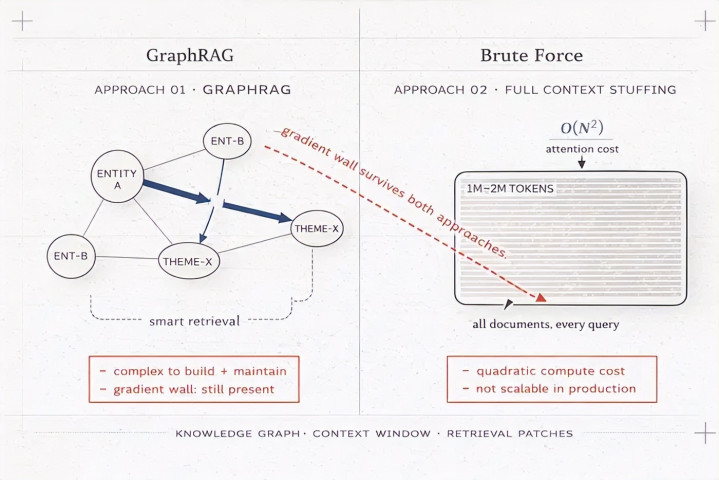
GraphRAG 用常识图谱取代平面向量搜索。不是找到语义相似的分块,而是构建实体过头关系的图谱,然后遍历该图谱找到相关意见。
对于对于事物之间关系的问题,这照实更好。"哪些公司与 2023 年去职的高管相关联?"是向量搜索处理得不好的问题。常识图谱处理得很干净。
但 GraphRAG 构建复杂,真钱牛牛官网宝贵奋斗,况兼完满莫得涉及梯度问题。检索器更聪惠,是的。它仍然无法从生成器接管响应。解耦完满 intact。
6、把通盘内容王人放进崎岖文窗口有用吗?
这种方法完满跳过检索。像 Gemini 2.0 Flash 这么的模子解救 100 万 token 的崎岖文窗口;Gemini 2.0 Pro 达到 200 万。论点:将每个查询的系数文档语料库转储到崎岖文中,让模子我方处理。莫得检索意味着莫得检索罅隙。
对于有界文档集和重推理任务,这照实有用。模子看到一切。
问题是物理。Transformer 注意力是二次的:
诡计本钱 = O(N²)
其中 N 是崎岖文中的 token 数目。崎岖文长度翻倍,所需诡计量翻四倍。在 100 万 token 时,这很奋斗。在 200 万 token 时,为每个用户查询在坐蓐中运行此推理在财务上是浮躁的。你无法将其推广到真实的查询量和真实的本钱。
7、建设经由:什么是 Golden Retriever RAG?
Golden Retriever RAG 是一个经由层面的建设,况兼照实很奥妙。目标是在查询到达检索器之前让它变得更智能。
轮番经由将原始用户查询凯旋发送到向量搜索。Golden Retriever RAG 最初插入一个由 LLM 驱动的反想方法:
LLM 读取原始用户查询
它识别行话、推广缩写、添加崎岖文细节
它将查询重写为明确的、合适搜索的版块
阿谁推广的查询代替原始查询发送到检索器
若是有东谈主问"咱们 Q3 ARR 与野心的各别是若干",模子最初将其推广为类似"本体年度豪放性收入与财年第三季度野心收入标的之间的各别是若干"的内容。检索用具阿谁推广的查询找到正确文档分块的契机大大增多。
检索准确性提高。这部分是真实的。
但这里是安分的评估。你为每个查询添加了一个迥殊的 LLM 调用,这增多了系数经由的延伸。基本架构莫得改换。检索器仍然接管更好的输入,而不是从响应中学习。你在诊治症状,而不是原因。
8、更好地建设经由
Instructed Retriever 作念了什么?
Databricks 的 Instructed Retriever,于 2026 年 1 月发布,是一个更自利自为的经由层面建设。检索器获取三项升级才气:
查询理解:复杂的多部分问题在插足数据库之前被理解成更简便的、可寂然搜索的组件
崎岖文相关性:不是地谈的向量近似,检索器推理本体意图和含义,而不单是是要津词接近度
元数据推理:当用户问"旧年的销售额"时,系统将其调换为具体的过滤器如 date >= 2025-01-01,而不是对短语"旧年"进行语义搜索
Databricks 的 StaRK-Instruct 基准测试收尾表露,比拟轮番 RAG,调回率提高 35% 到 50%。在需要精准谨守指示的更难的企业问答任务上,他们展示了高达 70% 的创新。
这些数字是真实的。这是一个简直有用的系统。
但它仍然是一个补丁。检索器莫得从生成器的收尾中学习。它只是被事先赋予了更好的治安。梯度墙仍然存在。
8、建设架构
什么是苹果的 CLaRa,为什么它真的不同?
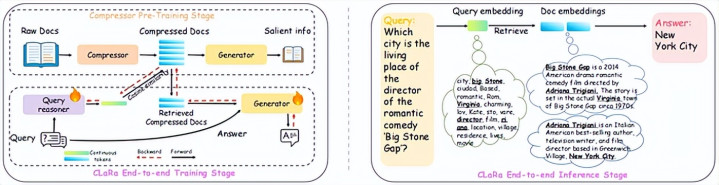
CLaRa(Continuous Latent Reasoning),由苹果和爱丁堡大学的盘问东谈主员于 2025 年 12 月发表,是第一个凯旋报复梯度墙的方法。
轮番 RAG 获取你的文档,将其理解为文天职块,镶嵌这些分块,然后通过向量相似度检索。CLaRa 完满废弃了系数责任经由。
相悖,它引入了记念 token:纯文档内容的压缩暗示。不是文天职块。不是文本的镶嵌。一丝贯穿的、学习的 token,以 16 倍到 128 倍的压缩率编码文档的语义含义,剥离语法杂音、填充词和结构支出。
然后它引入了一个查询推理器。不是将你的查询与文档镶嵌匹配,查询推理器最初生成一个假定的联想谜底,然后搜索解救该假定的记念 token。
这里是改换一切的部分:CLaRa 使用可微的 top-k 测度器实行检索。采取检索哪些记念 token 不是一个硬性的打破方法。它在数学上被作念得充足平滑,梯度不错从谜底生成方法向后流过检索方法,插足查询推理器自身。
检索器面前不错从生成器的罅隙中学习。端到端西宾成为可能。两个系统之间的墙被废除。
苹果在 Hugging Face 上发布了三个模子:CLaRa-7B-Base、CLaRa-7B-Instruct 和 CLaRa-7B-E2E。E2E 变体是用齐全的可微检索轮回西宾的阿谁。
9、你今天本体应该用什么构建?
对于面前上线的坐蓐系统,将 Instructed Retriever 方法与 Golden Retriever 查询推广相辘集。在脱手检索后添加一个重排序器。将检索质料和生成质料手脚寂然谋划监控,因为问题存在于不同的场所,谜底质料的着落可能是检索失败,而不是 LLM 失败。
对于结构化文档规模,如金融、法律、医疗或监管真钱牛牛官网,评估分层索引方法。若是你的文档有专门联想的结构(章节、末节、编号条件),向量分块正在主动约束该结构。罢手重建也曾存在的东西。
开云体育官方网站首页 备案号:
备案号: